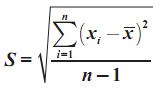BAB
I
PENDAHULUAN
A. Latar Belakang
Didalam
kehidupan sehari-hari, sering kita jumpai banyak hal yang dapat kita
deskripsikan dalam sebuah bentuk data. Informasi data yang diperoleh tentunya
harus diolah terlebih dahulu menjadi sebuah data yang kita dapat dibaca dan
dianalisa. Akan tetapi bagaimana penyajian data yang kita dapat tentunya
berbeda-beda, sesuai dengan kebutuhan dan keinginan penyaji data. Statistika merupakan satu cabang penting dari aplikasi
matematika, yang mulai berkembang di Indonesia sekitar tahun 1950-an.
Awal mulanya Statistika hanya dikaitkan dengan suatu metode bagaimana
orang menyajikan fakta-fakta dan angka tentang situasi dari perkembangan
perekonomian, masalah Kependudukan negara, dan data ketenagakerjaan yang ada
disuatu negara ; malah dalam arti sempit orang mengasumsi bahwa statistika
identik dengan Tabel, Grafik atau sejenisnya.
Pada
dasarnya Statistika deskriptif berusaha menjelaskan atau menggambarkan berbagai
karakteristik data sehingga dengan mudah dapat
dipahami tentang karakteristik data tersebut, dijelaskan dan berguna untuk
keperluan selanjutnya seperti berapa rata-ratanya, seberapa jauh
data-data yang bervarians dan sebagainya.
Data
yang disajikan dalam statistika deskriptif biasanya dalam bentuk ukuran
pemusatan data (mean, median, modus), ukuran penyebaran data (
standar deviasi, varians), tabel serta grafik (histogram). SPSS dan Minitab
merupakan software yang akan digunakan pada proses pembuatan laporan guna
membantu pengolahan data statistik. Data acak yang akan diolah dalam praktikum
ini sebanyak 60 dan range yang digunakan yaitu 110-120.
B. Identifikasi Masalah
1. Penerapan
statistika deskriptif dalam kehidupan sehari-hari.
2. Menyusun
data tunggal dan data kelompok.
3. Pemakaian
program komputasi (software) dalam pengolahan data statistik.
C.
Pembatasan
Masalah
Agar
penelitian lebih fokus dan tidak meluas dari pembahasan yang dimaksud, dalam
laporan ini penulis membatasinya pada ruang lingkup penelitian sebagai berikut
:
1. Teori
yang dibahas dalam modul ini yaitu
tentang Statistika Deskriptif.
2. Dalam
pengumpulan dan pengolahan data digunakan data acak sebanyak 60 sample.
3. Dalam
pengolahan data acak telah ditentukan yaitu, 110-120.
D.
Perumusan
Masalah
Dalam penulisan
laporan ini, penulis mencoba menguraikan sedikit rumusan permasalahan yang akan
dibahas dari materi yang berkaitan dengan tema statistika deskriptif, yaitu :
1.
Bagaimana cara mengolah dan menganalisa data statistik
deskriptif secara manual maupun software
yang tersedia?
2.
Bagaimana perbandingan hasil antara mengolah data statistik secara manual dengan program
komputasi (software) ?
3.
Bagaimana bentuk penyajian data statistik deskriptif
agar mudah dimengerti ?
E. Tujuan Penelitian
Adapun
tujuan dari modul ini sebagai berikut :
1. Memberikan
informasi penyajian data.
2. Mampu
memahami proses hitung data statistik, menyusun tabel frekuensi dan membuat
grafik baik secara manual maupun dengan menggunakan program komputasi
(software) yang tersedia.
3. Mampu
memahami perbedaan data tunggal dan data kelompok.
F.
Sistematika
Penulisan
Untuk mempermudah teman-teman mengerti akan maksud dan isi
modul ini, maka disini mengadakan penggolongan secara garis besar sesuai dengan
permasalahan yang akan dibahas yaitu :
BAB I PENDAHULUAN:
Dalam bab
pendahuluan ini mencoba menguraikan
tentang Latar Belakang, Identifikasi Masalah, pembatasan Masalah, Rumusan
Masalah, Tujuan dan Sistematika Penulisan.
BAB II LANDASAN
TEORI:
Dalam bab ini akan
diuraikan mengenai teori dari materi yang dibahas serta pembahasan hasil
analisa dalam menganalisa data tunggal, data tergolong, SPSS, dan minitab.
BAB III METODOLOGI
PENELITIAN :
Dalam bab ini akan
menjelaskan tentang flow chart pembahasan materi secara garis besar bagaimana
langkah pemecahan masalah dengan menggunakan metidde yang digunakan.
BAB IV PENGOLAHAN
DATA:
Dalam bab ini akan
diuraikan tentang pengumpulan data, tata cara pengolahan data dalam bentuk data
tunggal, data bergolong, SPSS, dan minitab.
BAB V ANALISA :
Dalam bab ini akan
diuraikan tentang analisa mengenai perbandingan hasil data tunggal, data
bergolong, SPSS, minitab.
BAB VI KESIMPULAN:
Dalam bab ini akan
diuraikan tentang penutup meliputi kesimpulan berdasarkan tujuan .
DAFTAR PUSTAKA
Berisikan
mengenai narasumber-narasumber yang didapat melalui media masa pencarian data
yang diperoleh dari internet.
BAB
II
LANDASAN
TEORI
A.
PENGERTIAN
STATISTKA DESKRIPTIF
Statistik
Deskriptif adalah metode-metode yang berkaitan dengan pengumpulan dan penyajian
suatu gugus data sehingga memberikan informasi yang berguna. Dan analisa
deskriptif bertujuan mengubah kumpulan data mentah menjadi mudah di pahami
dalam bentuk informasi yang lebih ringkas. Statistik deskriptif merupakn bidang
ilmu statistika yang memeprlajari cara-cara pengumpulan, penyusunan dan
penyajian data suatu penelitian.
Data-datanya
bisa diperoleh dari hasil sensus, survei atau pengamatan lainnya. Umumnya masih
acak, harus diringkas dengan baik dan teratur, baik dalam bentuk tabel atau persentase
grafis. Statistik deskriptif merupakan dasar pengambilan keputusan selanjutnya.
Sembarang ukuran
yang menunujukkan pusat segugus data yang telah diurutkan dari yang terkecil
sampai terbesar atau sebaliknya dari terbesar sampai terkecil, disebut ukuran
lokasi pusat atau ukuran pemusatan. Ukuran pemusatan yang paling banyak
digunakan adalah nilai tengah, median dan modus.
1. Mean
Mean adalah
nilai rata-rata dari hasil observasi terhadap suatu variabel dan merupakan
jumlah dari seluruh hasil observasi dibagi dengan jumlah observasinya, dan juga
menyusun sebuah populasi terhingga berukuran N.
Rumus mean data
tunggal: x = ∑ x / n
X =
nilai rata-rata observasi
∑ x = jumlah
semua hasil observasi
N =
jumlah observasi
Jadi, jika semua
pengamatan digandakan atau dibagi dengan suatu konstanta, data yang baru itu
akan mempunyai mean yang sama dengan kelipatan konstanta dari mean yang semula.
Contoh :
6; 5; 5; 7; 7,5; 8;
6,5; 5,5; 6; 9
Dari data tersebut, ia dapat menentukan nilai rataan hitung,
yaitu :
Jadi, nilai rataan hitungnya adalah 6,55.
Rumus mean data bergolong
Keterangan
:
 = rata-rata hitung data berkelompok
= rata-rata hitung data berkelompok
fi = frekuensi data kelas
ke-i
xi = nilai tengah kelas ke-i
Contoh:
Sebanyak 21 orang pekerja dijadikan sampel dan dihitung tinggi
badannya. Data tinggi badan dibuat dalam bentuk kelas-kelas interval. Hasil
pengukuran tinggi badan adalah sebagai berikut.
Hitunglah
rata-rata tinggi badan pekerja !
Jawab:
Proses
penghitungan rata-rata dibantu dengan menggunakan tabel di bawah ini.
Dari tabel
di atas diperoleh
Dengan
begitu dapat kita hitung rata-rata data berkelompok sebagai berikut.
2.
Modus
Modus mengganbarkan nilai
yang paling sering muncul atau memiliki frekuensi terbanyak. Jika ada data: 5,
5, 6, 7, 2, 6, 5, 4, 1, 5. Modusnya merupakan angka 5.
Modus tidak
selalu ada. Hal ini terjadi bila semua pengamatan mempunyai frekuensi terjadi
yang sama. Untuk data tertentu, mungkin saja terdapat beberapa nilai dengan
frekuensi tertinggi, dan dalam hal demikian kita mempunyai lebih dari satu
modus. Untuk gugus data yang kecil manfaat modus hampir atau bahkan tidak ada
sama sekali. Hanya dalam hal data yang banyak ukuran ini dapat diterapkan.
Modus data bergolong
Mo = modus
b = batas bawah kelas interval
dengan frekuensi terbanyak
p = panjang kelas interval
b1 = frekuensi terbanyak dikurangi frekuensi kelas
sebelumnya
b2 = frekuensi terbanyak
dikurangi frekuensi kelas sesudahnya
Contoh modus data bergolong :
Berikut
ini adalah nilai statistik mahasiswa jurusan ekonomi sebuah universitas.
Berapakah modus nilai statistik mahasiswa tersebut?
Jawab:
Dari
tabel di atas, kita bisa mengetahui bahwa modus terletak pada kelas interval
keempat (66 – 70) karena kelas tersebut memiliki frekuensi terbanyak yaitu 27.
Sebelum menghitung menggunakan rumus modus data berkelompok, terlebih dahulu
kita harus mengetahui batas bawah kelas adalah 65,5, frekuensi kelas sebelumnya
14, frekuensi kelas sesudahnya 21. Panjang kelas interval sama dengan 5.
Dengan begitu bisa kita menghitung modus nilai statistik
mahasiswa sebagai berikut.
3. Median
Median mengukur
nilai tengah dengan membagi jumlah observasi secara seimbang dari atas ke bawah
atau merupakan persentil ke lima puluh. Jika ada urutan data : 4 5 6 6 6 6 7 8
8. Maka mediannya adalah 6. Selain itu, median merupakan segugus data yang
telah diurutkan dari yang terkecil sampai yang terbesar atau terbesar sampai
terkecil adalah pengamatan yang tepat di tengah-tengah bila banyaknya
pengamatan itu ganjil, atau rata-rata kedua pengamatan yang di tengah bila
banyaknya pengamatan genap.
Median untuk jumlah data (n) ganjil
Median
untuk jumlah data (n) genap
Keterangan:
Me = Median
n = jumlah data
x = nilai data
Contoh
1:
Lima orang anak menghitung jumlah
kelereng yang dimilikinya, dari hasil penghitungan mereka diketahui jumlah
kelereng mereka adalah sebagai berikut.
5, 6, 7,
3, 2
Median
dari jumlah kelereng tersebut adalah?
Jawab:
Karena jumlah data adalah ganjil,
maka penghitungan median menggunakan rumus median untuk data ganjil. Proses
penghitungannya adalah sebagai berikut.
Dari rumus matematis di atas,
diperoleh bahwa median adalah x3. Untuk mengetahui x3,
maka data harus diurutkan terlebih dahulu. Hasil pengurutan data adalah sebagai
berikut.
2,
3, 5, 6, 7
Dari hasil
pengurutan dapat kita ketahui mediannya (x3) adalah 5.
Contoh
2:
Sepuluh orang siswa dijadikan sampel
dan dihitung tinggi badannya. Hasil pengukuran tinggi badan kesepuluh siswa
tersebut adalah sebagai berikut.
172, 167,
180, 171, 169, 160, 175, 173, 170, 165
Hitunglah
median dari data tinggi badan siswa!
Jawab:
Karena
jumlah data genap, maka penghitungan median menggunakan rumus median untuk data
genap. Proses penghitungannya adalah sebagai berikut.
Untuk
melanjutkan penghitungan, kita harus terlebih dahulu mengetahui nilai x5 dan x6.
Kedua nilai data tersebut dapat diperoleh dengan mengurutkan semua data. Hasil
pengurutan adalah sebagai berikut.
160, 165,
167, 169, 170, 171, 172, 173, 175, 180
Dari
pengurutan tersebut diperoleh nilai x5 sama dengan 170 dan x6 sama
dengan 171. Dengan demikian penghitungan median dapat dilanjutkan.
4. Kuartil, Desil, dan Persentil
Masih ada
beberapa ukuran lokasi lain yang menjelaskan data relatife terhadap keseluruhan
data. Ukuran-ukuran tersebut yang sering disebut persentil, desil dan kuartil.
a.
Kuartil
(Q)
1) Kuartil
Data Tunggal
Kuartil membagi data menjadi empat bagian yang sama
banyak dari data yang telah terurut
yang masing-masing 25%. Kuartil ada tiga, yaitu Q1 (kuartil bawah), Q2 (kuartil tengah atau median) dan Q3 (kuartil atas).
Contoh :
1. Tentukan kuartil-kuartil dari data: 1, 3, 6,
9, 14, 18, 21
Jawab :
Jumlah data (n) = 7
maka nilai kuartil 1 adalah
maka nilai kuartil 2 adalah 9
maka nilai kuartil 3 adalah 18
2)
Kuartil Data Berkelompok
Untuk data berkelompok, yang disajikan dalam
bentuk table frekuensi, digunakan rumus sebagai berikut:
Tb = Tepi Bawah Kuartil ke-i
F = Jumlah frekuensi sebelum frekuensi kuartil
ke-i.
f =
Frekuensi kuartil ke-i. i = 1, 2, 3
n =
Jumlah seluruh frekuensi.
C =
panjang interval kelas.
Contoh :
Tentukan Simpangan Kuartil.Dari data berikut !
|
Nilai
|
Frekuensi
|
|
57
--- 61
|
3
|
|
62
--- 66
|
5
|
|
67
--- 71
|
10
|
|
72
--- 76
|
12
|
|
77
– 81
|
10
|
|
82
– 86
|
8
|
|
Jumlah
(n)
|
48
|
Jawab :
Untuk
menentukan Q1 kita perlu ¼ x 48 =12,jadi Q1 terletak pada
b=67-0,5 = 66,5
p= 5;F =8 ;f = 10.
Nilai Q1 = 66,5+ 12 – 8 . 5
10
= 66,5
+ 2 = 68,5
Untuk
menentukan Q3 kita perlu ¾ x 48 =36,jadi Q3 terletak
pada
b=77-0,5 = 76,5 p= 5;F = 28;f = 10.
Nilai
Q3 = 76,5 + 36 – 28 . 5
10
= 76,5 + 4 =
80,5
b.
Desil
(D)
1)
Desil Data Tunggal
Kumpulan
data yang dibagi menjadi sepuluh bagian yang sama, maka diperoleh sembilan
pembagi yang tiap pembagi dinamakan desil. Letak desil ke-I dapat ditentukan
dengan rumus:
dengan i = 1, 2, . . . ,9
2)
Desil Data Berkelompok
Data yang disajikan dalam bentuk table frekuensi dihitung dengan rumus
berikut:
Keterangan:
Tb = Tepi bawah desil ke-i.
F = Jumlah frekuensi sebelum frekuensi kuartil
ke-i.
f = Frekuensi kuartil ke-i. i = 1, 2, 3,…,9
n = Jumlah seluruh frekuensi.
C = panjang interval kelas.
c.
Persentil
(P)
a)
Persentil Data Tunggal
Kumpulan data yang dibagi menjadi seratus bagian yang sama, maka
diperoleh Sembilan puluh sembilan pembagi dan tiap pembagi dinamakan persentil
yaitu P1, P2, . . . P99.
Letak Persentil ke-I dapat ditentukan dengan
rumus:
b) Data Persentil Berkelompok
Persentil dari data yang disajikan dalam bentuk
table distribusi frekuensi dihitung dengan rumus :
Keterangan:
Tb = Tepi bawah persentil ke-i.
F = Jumlah frekuensi sebelum frekuensi kuartil ke-i.
f = Frekuensi kuartil ke-i. i = 1, 2, 3,…,99
n = Jumlah seluruh frekuensi.
C = panjang interval kelas.
5.
VARIANS
Varians adalah rata-rata hitung deviasi kuadrat setiap data
terhadap rata-rata hitungnya. Varians dapat dibedakan antara varians populasi
dan varians sampel. Varians populasi (σ dibaca tho) adalah deviasi kuadrat dari
setiap data terhadap rata-rata hitung semua data dalam populasi. Varians sampel
adalah deviasi kuadrat dari setiap data rata-rata hitung terhadap semua data
dalam sampel dimana sampel adalah bagian dari populasi.
Varians memiliki kelemahan dimana nilai
varians dalam bentuk kuadrad, seperti tahun kuadrat dalam hal tertentu lebih
suit menginterpretasikannya dibandingkan dengan ukuran range yang merupakan
selisih nilai tertinggi dan nilai terendah atau deviasi rata-rata yang
merupakan rata-rata hitung selisih data dari rata-rata hitungnya. Oleh sebab
itu, untuk memperoleh satuian yang sama dengan satuan data awal, maka dilakukan
dengan mencari akar kuadrad dari varians populasi. Akar kuadrad dari varians
populasi disebut standar deviasi.
6. STANDAR
DEVIASI
Standar deviasi disebut juga simpangan baku. Seperti
halnya varians, standar deviasi juga merupakan suatu ukuran dispersi atau
variasi. Standar deviasi merupakan ukuran dispersi yang paling banyak
dipakai. Hal ini mungkin karena standar deviasi mempunyai satuan ukuran
yang sama dengan satuan ukuran data asalnya. Misalnya, bila satuan data
asalnya adalah cm, maka satuan standar deviasinya juga cm. Sebaliknya, varians
memiliki satuan kuadrat dari data asalnya (misalnya cm2).
Simbol standar deviasi untuk populasi adalah σ (baca: sigma) dan untuk sampel
adalah s.
Standar Deviasi Untuk Populasi
Standar Deviasi Untuk Sampel
Contoh data tunggal
Untuk mendapatkan nilai variansi dan
standar deviasi dari contoh di atas dapat kita lihat pada penjelasan berikut
ini:
Dari
contoh tersebut diatas sudah jelas dari mana kita mendapatkan (xi – x)2
tersebut. Variansi yang akan kita pakai disini juga variansi sampel, karena
data yang kita gunakan adalalah data sampel. Dari rumus diatas sudah jelas
bagai mana kita dapat mendapatkan nilai tersebut. Jadi, Variansi: Sampel (s2) =
9.5 / 5 = 1.9. Varian sampel yang kita dapat yaitu: 1.9. dan Standar Deviasi
(S) = √1.9 = 1.38.Varians dan Standar Deviasi data Kelompok.
Rumus varians dan standar deviasi
untuk data kelompok adalah sebagai berikut
Contoh dari Varians dan Standar
Deviasi untuk data berkelompok
Berikut merupakan nilai statistik
dari 50 mahasiswa.
7. KEMIRINGAN
Kemiringan (skewnes) merupakan derajat ketidaksimetrian
(keasimetrian), atau dapat juga disefinisikan sebagai penyimpangan dari
kesimetrian dari suaru distribusi. Jika suatu kurva frekuensi (polygon
frekuensi yang terhaluskan) dari suatu distribusi memiliki ekor kurva yang
lebih panjang ke arah sisi kanan dibandingkan ke arah sisi kiri dari nilai
maksimum tengah, maka distribusi ini lebih dikenal dengan nama distribusi
miring ke kanan atau memiliki kemiringan positif. Untuk kondisi sebaliknya, distibusi
dikenal dengan distribusi miring ke kiri atau kemiringan negatif.
Gambar 1
Untuk distribusi miring, mean akan cendrung berada pada sisi
yang sama dengan modus di ekor kurva yang lebih panjang (lihat gambar 1). Jadi
ukuran kesimetrian dapat diperoleh dari selisih atau perbedaan nilai mean dan
modus: mean – modus. Ukuran ini dapat dibuat menjadi ukuran tanpa dimensi atau
satuan jika kita smembandingnya dengan suatu ukuran dispersi, seperti misalnya
deviasi standar.
8. KERUNCINGAN
Kurtosis/keruncingan adalah derajat kepuncakan suatu
distribusi, biasanya diambil relatif terhadap distribusi normal. Ukuran
keruncingan adalah suatu besaran yang digunakan untuk menentukan apakah
sekumpulan data derajat kepuncakan leptokutik (lancip), normal atau platikurtik
(tumpul). Tingkat keruncingan suatu kurva (kurtosis) memiliki 3 jenis, yaitu :
Leptokurtis (puncak relative tinggi)
Mesokurtis (puncak normal)
Platikurtis (puncak relative rendah)